This is the last part of the optimization project.
I choose the "Zopfli" open source for optimization.
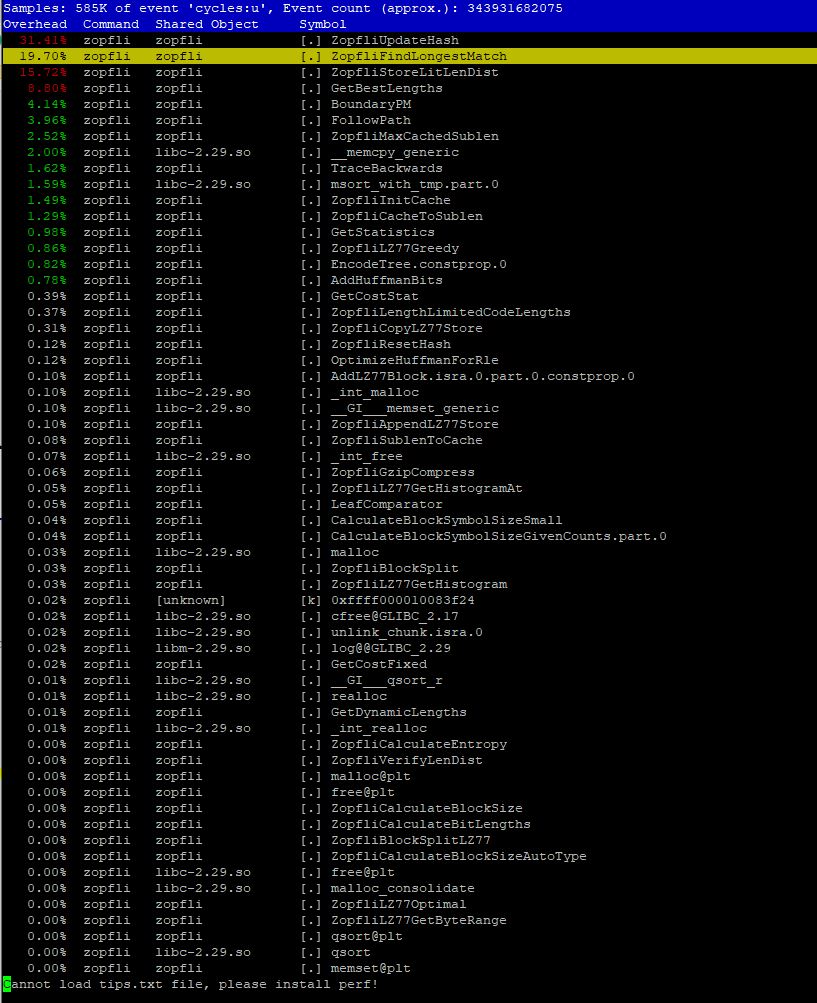
As a result of profiling, the hottest part of Zopfli is the "ZopfliUpdateHash()" function.
Here is the result of profiling.


Here is the hottest part in the "ZopfliUpdateHash()" function.
Here is the "ZopfliUpdateHash" function code in hash.c .

I plan to optimize "while loof" in this function as profiling result with several options.

First, GCC optimization options.
When I change GCC option with -o flag, the result is very interesting. I changed only the option 0 to 3 and fast, the results are quite different. when choose the -o fast, real and sys time is faster. Aslo, when compare option o0 to o3, when the option was increased, the speed also faster.
-O0- no optimization
-O1- first level optimization
-O2 – second level optimization
-O3 – highest optimization
-Ofast – optimize for speed only
time
|
-O0
|
-O1
|
-O2
|
-O3
|
-Ofast
|
real
|
3m39.489s
| 1m41.897s | 1m33.908s | 2m19,740s | 1m23.712s |
user
|
3m39.023s
| 1m41.606s | 1m33.620s | 1m22.996s |
1m23.455s
|
sys
|
0m0.142s
| 0m0.127s | 0m0.138s | 0m0.163s | 0m0.119s |
Second, Code Rewriting optimizations
* Original code
while (pos + amount + 1 < end && array[pos] == array [pos + amount +1]
&& amount < (unsigned short)(-1)){
amount++;
}
|
1) Common subexpression elimination.
In this while loof code, subexpression(pos + amount +1) is evaluated twice. It could be evaluated once and used twice, saving an expensive it.
size_t newVal = pos +1;
while( newVal < end && array[pos] == array[bewVa] && amount < )unsigned short)(-1){
amount ++;
newVal= newVal + amount ;
} |
2) Short Circuit
In this while loof, there are three conditions. when evaluating a condition with a logical AND, both halves of the condition must be true for the entire condition to be true. therore, it is not necessary to evaluate the second, third of the condition if the first is false.
int newVal = pose + 1;
while( newVal < end){
while (array[pos] == array[bewVa]){
while (amount < )unsigned short)(-1){
amount ++;
newVal= newVal+ amount ;
}}} |
Third, SIMD
Vectorization is the unrolling of a loop combined with the generation of packed SIMD
instructions by the compiler. Because the packed instructions operate on more than one
data element at a time, the loop can execute more efficiently. It is sometimes referred to
as auto-vectorization, to emphasize that the compiler identifies and optimizes suitable
loops on its own, without requiring any special action by the programmer.
* Original code
void ZopfliUpdateHash(const unsigned char* array, size_t pos, size_t end, ZopfliHash* h) { .......
......
while (pos + amount + 1 < end &&
array[pos] == array[pos + amount + 1] && amount < (unsigned short)(-1)) {
amount++;
}
.....
......
}
|
* optimization code
Inform to the compiler that no overlap is possible. This is done in standard C by using the
restrict qualifier for the pointers.
void ZopfliUpdateHash(const unsigned char* restrict array, size_t pos, size_t end, ZopfliHash* restrict h) { .......
......
while (pos + amount + 1 < end &&
array[pos] == array[pos + amount + 1] && amount < (unsigned short)(-1)) {
amount++;
}
.....
......
}
|
Finally, I will try to optimize "zopfliUpdateHash()" with below code.
void ZopfliUpdateHash(const unsigned char* restrict array, size_t pos, size_t end, ZopfliHash* restrict h) { .......
......
while (newVal < end ){
while ( array[pos] == array[newVal ] {
while( amount < (unsigned short)(-1)) {
amount++;
newVal = newVal + amount ;
}}}
.....
......
}
|
What I learn...
During this project, I learned two things.
First, when I do coding, I have to think whether my code is optimized. My coding style can affect to the processing speed. so, during programming, I have to consider about the speed. Second, there are variety way for optimization. My optimization plan are some of them. I will try to learn other way. This project is very interesting.